CNRI & GigaBit Testbed Initiative
Executive Summary
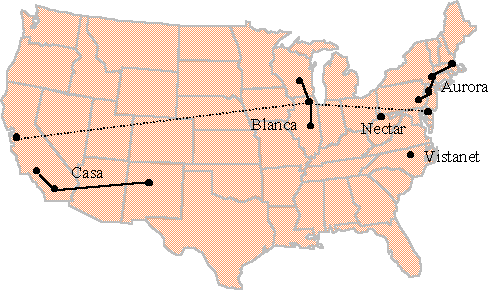
Five Testbeds, named Aurora, Blanca, Casa, Nectar and Vistanet, were established and used over a period of several years to explore advanced networking issues, to investigate architectural alternatives for gigabit networks, and to carry out a wide range of experimental applications in areas such as weather modeling, chemical dynamics, radiation oncology, and geophysics data exploration. The five testbeds were geographically distributed across the United States as shown in the figure below.
The Gigabit Testbeds:
A key decision in the effort, therefore, was to make use of experimental technologies that were appropriate for gigabit networking. The emphasis was placed on fundamental systems issues involved with the development of a technology base for gigabit networking rather than on test and evaluation of individual technologies. ATM, SONET and HIPPI were three of the technologies used in the program. As a result, the impetus for industry to get these technologies to market was greatly heightened. Many of the networks that subsequently emerged, such as the NSF-sponsored vBNS and the DOD-sponsored DREN, can be attributed to the success of the gigabit testbed program.
The U.S. Government funded this effort with a total of approximately $20M over a period of approximately five years, with these funds used by CNRI primarily to fund university research efforts. Major contributions of transmission facilities and equipment were donated at no cost to the project by the carriers and computer companies, who also directly funded participating researchers in some cases. The total value of industry contributions to the effort was estimated to be perhaps 10 or 20 times greater than the Government funding. The coordinating role of a lead organization, played by CNRI, was essential in helping to bridge the many gaps between the individual research projects, industry, government agencies and potential user communities. At the time this effort began, there did not appear to be a clearly visible path to make this kind of progress happen.
Initiative Impacts
In addition to the many technical contributions resulting from the testbeds, a number of non-technical results have had major impacts for both education and industry.
First and foremost was a new model for network research provided by the testbed initiative. The bringing together of network and application researchers, integration of the computer science and telecommunications communities, academia-industry-government research teams, and government-leveraged industry funding, all part of a single, orchestrated project spanning the country, provided a new level of research collaboration not previously seen in this field. The Initiative created a community of high performance networking researchers that crossed academic/industry/government boundaries.
The coupling of application and networking technology research from project inception was a major step forward for both new technology development and applications progress. Having applications researchers involved from the start of the project allowed networking researchers to obtain early feedback on their network designs from a user’s perspective, and allowed network performance to be evaluated using actual user traffic. Similarly, application researchers learned how network performance impacted their distributed application designs through early deployment of prototype software. Perhaps most significantly, researchers could directly investigate networked application concepts without first waiting for the new networks to become operational, opening them to new possibilities after decades of constrained bandwidth.
The collaboration of computer network researchers, who came primarily from the field of computer science, and the carrier telecommunications community provided another important dimension of integration. The development of computer communications networks and carrier-operated networks have historically proceeded along two separate paths with relatively little cross-fertilization. The testbeds allowed each community to work closely with the other, allowing each to better appreciate the other’s problems and solutions and leading to new concepts of integrated networking and computing.
From a research perspective, the testbed initiative created close collaborations among investigators from academia, government research laboratories, and industrial research laboratories. Participating universities included Arizona, UCBerkeley, Caltech, Carnegie-Mellon, Illinois, MIT, North Carolina, Pennsylvania and Wisconsin; national laboratories included Lawrence Berkeley Laboratory, Los Alamos National Laboratory (LANL), and JPL, and the NSF-sponsored National Center for Supercomputer Applications, Pittsburgh Supercomputer Center, and San Diego Supercomputer Center, while industry research laboratories included IBM Research, Bellcore, GTE Laboratories, AT&T Bell Laboratories, BellSouth Research, and MCNC. The collaborations also included facilities planners and engineers from the participating carriers, which included Bell Atlantic, BellSouth, AT&T, GTE, MCI, NYNEX, Pacific Bell and US West.
Another important dimension of the testbed model was its funding structure, in which government funding was used to leverage a much larger investment by industry. A major industry contribution was made by the carriers in the form of SONET and other transmission facilities within each testbed at gigabit or near-gigabit rates. The value of this contribution cannot be overestimated, since not only were such services otherwise non-existent at the time the project began, but they would have been unaffordable to the research community if they had existed under normal tariff conditions. By creating an opportunity for the carriers to learn about potential applications of high speed networks while at the same time benefiting from collaboration with the government-funded researchers in network technology experiments, the carriers were, in turn, willing to provide new high-speed wide-area experimental transmission facilities and equipment and to fund the participation of their researchers and engineers.
The Initiative resulted in significant technology transfer to the commercial sector. As a direct result of their participation in the project, two researchers at Carnegie-Mellon University founded a local-area ATM switch startup company, FORE Systems. This was the first such local ATM company formed, and provided a major stimulus for the emergence of high speed local area networking products. It also introduced to the marketplace the integration of advanced networking concepts with advanced computing architectures used within their switch.
Other technology transfers included software developed to distribute and control networked applications, the HIPPI measurement device (known as Hilda) developed by MCNC as part of the Vistanet effort, and the HIPPI-SONET wide-area gateway developed by LANL for the Casa testbed. In addition, new high speed networking products were developed by industry in direct response to the needs of the testbeds, for example HIPPI fiber optic extenders and high speed user-side SONET equipment. Major technology transfers also occurred through the migration of students who had worked in the testbeds to industry to implement their work in company products.
At the system level, the testbeds led directly to the formation of three statewide high speed initiatives undertaken by carriers participating in the testbeds. The North Carolina Information Highway (NCIH) was formed by BellSouth and GTE as a result of their Vistanet testbed involvement to provide an ATM/SONET network throughout the state. Similarly, the NYNET experimental network was formed in New York state by NYNEX as a result of their Aurora testbed involvement, and the California Research and Education Network (CalREN) was created by Pacific Bell following their Casa testbed participation.
The testbed initiative also led to the early use of gigabit networking technology by the defense and intelligence communities for experimental networks and global-scale systems, which have become the foundation for a new generation of operational systems. More recently, the U.S. Government has begun to take steps to help create a national level wide-area Gigabit networking capability for the research community.
The key technical areas addressed in the initiative are categorized for this report as transmission, switching, interworking, host I/O, network management, and applications and support tools. In each case, various approaches were analyzed and many were tested in detail. A condensed summary of the key investigations and findings is given at the end of the executive summary and elaborated on more fully in the report.
Future Directions
Among the barriers most often cited to the widespread deployment of very high-speed networks, those often cited are costs of the technology (particularly the cost of its deployment over large geographic areas), the regulated nature of the industry, and lack of market forces for applications that could make use of it and sustain its advance. Moreover, most people find it difficult to invest their own time or resources in a new technology until it becomes sufficiently mature that they can try it out and visualize what they might do with it and when they might use it.
A recent National Research Council report [1] includes a summary of the major advances in the computing and communications fields from the beginning of time-sharing through scalable parallel computing, just prior to when the gigabit testbeds described in this report were producing their early results. Using that report’s model, the gigabit testbeds would be characterized as being in the early conceptual and experimental development and application phase. The first technologies were emerging and people were attempting to understand what could be done with them, long before there was an understanding of what it would take to engineer and deploy the technologies on a national scale to enable new applications not yet conceived.
The Gigabit Testbed Initiative produced a demonstration of what could be done in a variety of application areas, and it motivated people in the research community, industrial sector, and government to provide a foundation for follow-on activities. Within the Federal government, the testbed initiative was a stimulus for the following events:
· The HPCCIT report on Information and Communication Futures identified high performance networking as a Strategic Focus.
· The National Science and Technology Council, Committee on Computing and Communications held a two day workshop which produced a recommendation for major upgrades to networking among the HPC Centers to improve their effectiveness, and to establish a multi-gigabit national scale testbed for pursuing more advanced networking and applications work.
· The first generation of scalable networking technologies emerged based on scalable computing technologies.
· The DoD HPC Modernization program initiated a major upgrade in networking facilities for their HPC sites.
· The Advanced Technology Demonstration gigabit testbed in the Washington DC area was implemented.
· The defense and intelligence communities began to experiment with higher performance networks and applications.
· The NSF Metacenter and vBNS projects were initiated.
· The all-optical networking technology program began to produce results with the potential for 1000x increase in transmission capacity.
To initiate the next phase of gigabit research and build on the results of the testbeds, CNRI proposed that the Government continue to fund research on gigabit networks using an integrated experimental national gigabit testbed involving multiple carriers, with gigabit backbone links provided over secondary (i.e., backup) channels by the carriers at no cost and switches and access lines paid for by the Government and participating sites. However, costs for access lines proved to be excessive, and at the time the Government was also unable to justify the funding needed for a national gigabit network capability — instead, several efforts were undertaken by the Government to provide lower speed networks.
In the not-too-distant future, we expect the costs for accessing a national gigabit network on a continuing basis will be more affordable and the need for it will be more evident, particularly its potential for stimulating the exploration of new applications. The results of the gigabit testbed initiative have clearly had a major impact on breaking down the barriers to putting high performance networking on the same kind of growth curve as high performance computing, thus enabling a new generation of national and global-scale high performance systems which integrate networking and computing.
Investigations and Findings
Four distinct end-to-end network layer architectures were explored in the project. These were a result both of architecture component choices made by researchers after the work was underway and of the a priori testbed formation process. The architectures were (1) seamless WAN-LAN ATM and (2) seamless WAN-LAN PTM, both used in the Aurora testbed, (3) heterogeneous wide-area ATM/local-area networks, used in the Blanca, Nectar and Vistanet testbeds, and (4) wide-area HIPPI/SONET via local switching, used in the Casa testbed.
The following summaries present highlights of the technology and applications investigations. It should be noted that while some efforts are specific to their architectural contexts, in many cases, the results can be applied to other architectures including architectures not considered in the initiative.
Transmission
· OC-48 SONET links were installed in four testbeds over distances of up to 2000 km, accelerating vendor development and carrier deployment of high speed SONET equipment, establishing multiple-vendor SONET interconnects, enabling discovery and resolution of standards implementation compatibility problems, and providing experience with SONET error rates in an operational environment
· Testbed researchers developed a prototype OC-12c SONET cross-connect switch and investigated interoperation with carrier SONET equipment, and developed OC-3c, OC-12, and OC-12c SONET interfaces for hosts, gateways and switches; these activities provided important feedback to SONET chip developers
· Techniques for carrying variable-length packets directly over SONET were developed for use with HIPPI and other PTM technologies, with both layered and tightly coupled approaches explored
· An all-optical transmission system – the first carrier deployment of this technology – was installed and used to interconnect ATM switches over a 300 mile distance using optical amplifier repeaters
· HIPPI technology was used for many local host links and for metropolitan area links through the use of HIPPI extenders and optical fiber; other local link technologies included Glink and Orbit
· Several wide-area striping approaches were investigated as a means of deriving 622 Mbps and higher bandwidths from 155 Mbps ATM or SONET channels; configurations included end-to-end ATM over SONET, LAN-WAN HIPPI over ATM/SONET, and LAN-WAN HIPPI and other variable-length PDUs directly over SONET
· A detailed study of striping over general ATM networks concluded that cell-based striping should be used. This capability can be introduced at LAN-WAN connection points in conjunction with destination host cell re-ordering and an ATM-layer synchronization scheme
Switching
· Prototype high speed ATM switches were developed (or made available) by industry and deployed for experiments in several of the testbeds, supporting 622 Mbps end-to-end switched links using both 155 Mbps striping and single-port 622 Mbps operation
· The first telco central office broadband ATM switch was installed and used for testbed experiments, using OC-12c links to customer premises equipment and OC-48 trunking
· Wide-area variable-length PTM switching was developed and deployed in the testbeds using both IBM’s Planet technology and HIPPI switches in conjunction with collocated wide-area gateways
· Both ATM and PTM technologies were developed and deployed for both local and desk area networking (DAN) experiments, along with the use of commercial HIPPI and ATM switches, which became available as a result of testbed-related work
· A TDMA technique was developed and applied to tandem HIPPI switches to demonstrate packet-based quality-of-service operation in HIPPI circuit-oriented switching environments, and a study of preemptive switching of variable length packets indicated a ten-fold reduction in processing requirements was possible relative to processor-based cell switching
Interworking
· Three different designs were implemented to interwork HIPPI with wide-area ATM networks over both SONET and all-optical transmission infrastructures; explorations included the use of 4×155 Mbps striping and non-striped 622 Mbps access, local HIPPI termination and wide-area HIPPI bridging; resulting transfer rates ranged from 370 to 450 Mbps
· A HIPPI-SONET gateway was implemented which allowed transfer of full 800 Mbps HIPPI rates across striped 155 Mbps wide-area SONET links; capabilities included variable bandwidth allocation of up to 1.2 Gbps and optional use of forward error correction, with a transfer rate of 790 Mbps obtained for HIPPI traffic (prior to host protocol processing)
· Seamless ATM DAN-LAN-WAN interworking was explored through implementation of interface devices which provided physical layer interfacing between 500 Mbps DAN Glink transmission, LAN ATM switch ports, and a wide-area striped 155 Mbps ATM/SONET network.
Host I/O
· Several different testbed investigations demonstrated the feasibility of direct cell-based ATM host connections for workstation-class computers; this work established the basis for subsequent development of high speed ATM host interface chipsets by industry and provided an understanding of changes required to workstation I/O architectures for gigabit networking
· Variable-length PTM host interfacing was investigated for several different types of computers, including workstations and supercomputers; in addition to vendor-developed HIPPI interfaces, specially developed HIPPI and general PTM interfaces were used to explore the distribution of high speed functionality between internal host architectures and I/O interface devices
· TCP/IP investigations concluded that hardware checksumming and data-copying minimization were required by most testbed host architectures to realize transport rates of a few hundred Mbps or higher; full outboard protocol processing was explored for specialized host hardware architectures or as a workaround for existing software bottlenecks
· A 500 Mbps TCP/IP rate was achieved over a 1000-mile HIPPI/SONET link using Cray supercomputers, and a 516 Mbps rate measured for UDP/IP workstation-based transport over ATM/SONET. Based on other workstation measurements, it was concluded that, with a 4x processing power increase (relative to the circa 1993 DEC Alpha processor used), a 622 Mbps TCP/IP rate could be achieved using internal host protocol processing and a hardware checksum while leaving 75% of the host processor available for application processing
· Measurements comparing the XTP transport protocol with TCP/IP were made using optimized software implementations on a vector Cray computer; the results showed TCP/IP provided greater throughput when no errors were present, but that XTP performed better at high error rates due to its use of a selective acknowledgment mechanism
· Presentation layer data conversions required by applications distributed over different supercomputers were found to be a major processing bottleneck; by exploiting vector processing capabilities, revisions to existing floating point conversion software resulted in a fifty-fold increase in peak transfer rates
· Experiments with commercial large-scale parallel processing architectures showed processor interconnection performance to be a major impediment to gigabit I/O at the application level; an investigation of data distribution strategies led to use of a reshuffling algorithm to remap the distribution within the processor array for efficient I/O
· Work on distributed shared memory (DSM) for wide-area gigabit networks resulted in several latency-hiding strategies for dealing with large propagation delays, with relaxed cache synchronization resulting in significant performance improvements
Network Management
· In different quality-of-service investigations, a real-time end-to-end protocol suite was developed and successfully demonstrated using video streams over HIPPI and other networks, and a `broker’ approach was developed for end-to-end/network quality-of-service negotiations in conjunction with operating system scheduling for strict real-time constraints
· An evaluation of processing requirements for wide-area quality-of-service queuing in ATM switches, using a variation of the “weighted fair queuing” algorithm, found that a factor of 8 increase in processing speed was needed to achieve 622 Mbps port speeds relative to the i960/33MHz processor used for the experiments
· Congestion/flow control simulation modeling was carried out using testbed application traffic, with the results showing rapid ATM switch congestion variations and high cell loss rates; also, a speedup mechanism was developed for lost packet recovery in high delay-bandwidth product networks using TCP’s end-to-end packet window protocol
· An end-to-end time window approach using switch monitoring and feedback to provide high speed wide-area network congestion control was developed, and performance was consistent with simulation-based predictions
· A control and monitoring subsystem was developed for real-time traffic measurement and characterization using carrier-based 622 Mbps ATM equipment; the subsystem was used to capture medical application traffic statistics revealing that ATM cell traffic can be more bursty than expected, dictating larger amounts of internal switch buffering than initially thought necessary for satisfactory performance
· A data generation and capture device for 800 Mbps HIPPI link traffic measurement and characterization was developed and commercialized, and was used for network debugging and traffic analysis; more generally, many network equipment problems were revealed through the use of real application traffic during testbed debugging phases
Applications and Support Tools
· Investigations using quantum chemical dynamics modeling, global climate modeling, and chemical process optimization modeling applications identified pipelining techniques and quantified speedup gains and network bandwidth requirements for distributed heterogeneous metacomputing using MIMD MPP, SIMD MPP, and vector machine architectures
· Most of the applications that were tested realized significant speedups when run on multiple machines over a very high speed network; however, a superlinear speedup of 3.3 was achieved using two dissimilar machines for a chemical dynamics application; other important benefits of distributed metacomputing such as large software program collaboration-at-a-distance were also demonstrated, and major advances made in understanding how to partition application software
· Homogeneous distributed computing was investigated for large combinatorial problems through development of a software system which allows rapid prototyping and execution of custom solutions on a network of workstations, with experiments providing a quantification of how network bandwidth impacts problem solution time
· Several distributed applications involving human interaction in conjunction with large computational modeling were investigated; these included medical radiation therapy planning, exploration of large geophysical datasets, and remote visualization of severe thunderstorm modeling
· The radiation therapy planning experiments successfully demonstrated the value of integrating high performance networking and computing for real-world applications; other interactive investigations similarly resulted in new levels of visualization capability, provided new techniques for distributed application communications and control, and provided important knowledge about host-related problems which can prevent gigabit speed operation
· A number of software tools were developed to support distributed application programming and execution in heterogeneous environments; these included systems for dynamic load balancing and checkpointing, program parallelization, communications and runtime control, collaborative visualization, and near-realtime data acquisition for monitoring progress and for analyzing results.
1 Introduction

The Initiative had two main goals, both of which were premised on the use of network testbeds: (1) to explore technologies and architectures for gigabit networking, and (2) to explore the utility of gigabit networks to the end user. In both cases the focus was on providing a data rate on the order of 1 Gbps to the end-points of a network, i.e., the points of user equipment attachment, and on maximizing the fraction of this rate available to a user application.
A key objective of the Initiative was to carry out this research in a wide-area real-world context. While the technology for user-level high-speed networking capability could be directly achieved by researchers in a laboratory setting circa 1990, extending this context to metropolitan or wide-area network distances at gigabit per second rates was virtually impossible, due both to the absence of wide-area transmission and switching equipment for end-user gigabit rates and to the lack of market motivation to procure and install such equipment by local and long-distance carriers.
To solve this “chicken-and-egg” problem, a collaborative effort involving both industry and the research communities was established by CNRI with funding from government and industry. NSF and ARPA jointly provided research funding for the participating universities and national laboratories, while carriers and commercial research laboratories provided transmission and switching facilities and results from their internally-funded research. Five distinct testbed collaborations were created. These were called Aurora, Blanca, Casa, Nectar, and Vistanet. (A sixth gigabit testbed called MAGIC [7] was funded by DARPA about 18 months later, but was managed as a separate project and is not further described in this report.)
Each testbed had a different set of research collaborators and a different overall research focus and objectives. At the same time, there were also common areas of research among the testbeds, allowing different solutions for a given problem to be explored.
The remainder of this report is organized as follows. Section 2, The Starting Point, briefly describes the technical context for the project which existed in the 1989-90 timeframe. Section 3, Structure and Goals, gives an overview of the Initiative structure, including the participants, topology and goals of each testbed. The main body of the report is contained in Section 4, Investigations and Findings, which brings together by technical topic the major work carried out in the five testbeds. Section 5, Conclusion, summarizes the impacts of the Initiative and how they might relate to the future of very high speed networking research. Appendix A lists reports and publications generated by the testbeds during the course of the project.
Readers are strongly encouraged to consult the testbed references and publications for more comprehensive and detailed discussions of testbed accomplishments. This report summarizes much of that work, but is by no means a complete cataloging of all efforts undertaken.
2 The Starting Point
Computer networking dates from the late 1960s, when affordable minicomputer technology enabled the implementation of wide-area packet switching networks. The Arpanet, begun in 1969 as a research project by DARPA, provided a focal point within the U.S. for packet network technology development. In the 1970s, parallel development by DARPA of radio and satellite-based packet networks and TCP/IP internetworking technology resulted in the establishment of the Internet. The subsequent introduction and widespread use of ethernet, token ring and other LAN technologies in the 1980s, coupled with the expansion of the Internet by NSF to a broader user base, led to increasing growth and a transition of the Internet to a self-supporting operational status in the 1990s.
Wide-area packet switching technology has from its inception made use of the telephone infrastructure for its terrestrial links, with the packet switches forming a network overlay on the underlying carrier transmission system. The links were initially 50 Kbps leased lines in the original Arpanet, progressing to 1.5 Mbps T1 lines in the NSFNET circa 1988 and 45 Mbps T3 lines by about 1992. Thus, at the time the gigabit testbed project began, Internet backbone speeds and large-user access lines were in the 50 Kbps to 1.5 Mbps range and local-area aggregate speeds were typically 10 Mbps or less. Individual peak user speeds ranged from about 1 Mbps for high-end workstations to 9.6 Kbps or less for PC modem connections.
The dominant application which emerged on the Arpanet once the network became usable was not what had been expected when the network was planned. Conceived as a vehicle for resource sharing among the host computers connected to the network, people-to-people communication in the form of email quickly came to dominate network use. The ability to have extended conversations without requiring both parties to be available at the same time, being able to send a single message to an arbitrarily large set of recipients, and automatically having a copy of every message stored in a computer for future reference proved to be powerful stimuli to the network’s use, and is an excellent example of the unforeseen consequences of making a new technology available for experimental exploration.
The computer resource sharing which did take hold was dominated by two applications-namely, file transfer and remote login. Applications which distributed a problem’s computation among computers connected to the network were also attempted and in some cases demonstrated, but they did not become a significant part of the original Arpanet’s use. Packetized voice experiments were demonstrated over the Arpanet in the 1970s, but with limited applicability due to limited bandwidth and long store-and-forward transmission delays at the switches.
The connection of the NSF-sponsored supercomputer centers to the Internet in the late 1980s provided a new impetus for networked resource sharing and resulted in an increase of activity in this application area, but multi-computer explorations were severely limited by network speeds.
2.2 State of Very High-Speed Networking in 1989-90
Prior to the time the testbeds were being formed in 1990, very little hands-on research in gigabit networking was taking place. Work by carriers and equipment vendors focused primarily on higher transmission speeds rather than on networking. There was a good deal of interest in high-speed networking within the research community, consisting mostly of paper studies and simulations, along with laboratory work at the device level. Interest was stimulated in the telecommunications industry by ongoing work on the standardization of Broadband ISDN (B-ISDN), which was intended to eventually address user data rates from about 50 Mbps upwards to the gigabit/s region, within the scientific community, interest in remote data visualization and multi-processor supercomputer-related activities was high.
A few high speed technologies had emerged by 1989, most notably HIPPI and Ultranet for local connections between computers and peripherals. HIPPI, developed at Los Alamos National Laboratory (LANL), was in the process of standardization at the time by an ANSI subcommittee and had been demonstrated with laboratory prototypes. Ultranet was based on proprietary protocols, and Ultranet products were in use at a small number of supercomputer centers and other installations. Both technologies provided point-to-point links between hosts at data rates of 800 Mbps to 1 Gbps.
In wide-area networking, SONET (Synchronous Optical Network) was being defined as the underlying transmission technology for the U.S. portion of B-ISDN by ANSI, and its European counterpart SDH (Synchronous Digital Hierarchy) was undergoing standardization by the CCITT. SONET and SDH were designed to provide wide-area carrier transport at speeds from approximately 50 Mbps to 10 Gbps and higher, along with the associated monitoring and control functions required for reliable carrier operation. While non-standard trunks were already in operation at speeds on the order of a gigabit/s, the introduction of SONET/SDH offered carriers the use of a scalable, all-digital standard with both flexible multiplexing and the prospect of ready interoperability among equipment developed by different vendors.
A number of high-speed switch designs were underway at the time, most focused on ATM cell switching. Examples of ATM switch efforts included the Sunshine switch design at Bellcore and the Knockout switch design at AT&T Bell Labs. Exploration of variable length packet switching at gigabit speeds was also taking place, most notably by the PARIS (later renamed Planet) switch effort at IBM. These efforts were focused on wide-area switching environments – investigation of ATM for local area networking had not yet begun.
Computing performance in 1990 was dominated by the vector supercomputer, with highly parallel supercomputers still in the development stage. The fastest supercomputer, the CRAY-YMP, achieved on the order of 1-2 gigaflops in 1990, while the only commercial parallel computer available was the Thinking Machines Corporation CM-2. Workstations had peak speeds in the 100 MIPS range, with PCs in about the 10 MIPS range. I/O interfaces for these machines consisted mainly of 10 Mbps ethernet and other LAN technologies with similar speeds, with some instances of 100 Mbps FDDI beginning to appear.
Optical researchers were making significant laboratory advances by 1990 in the development of optical devices to exploit the high bandwidth inherent in optical fibers, but this area was still in a very early stage with respect to practical networking components. Star couplers, multiplexors, and dynamic tuners were some of the key optical components being explored, along with several all-optical local area network designs.
The data networking research community had begun to focus on high-speed networking by the late 1980s, particularly on questions concerning protocol performance and flow/congestion control. New transport protocols such as XTP and various lightweight protocol approaches were being investigated through analysis, simulation, and prototyping, and a growing amount of conference and journal papers were focusing on high-speed networking problems.
The regulatory environment which existed in 1990, at the time the Gigabit Testbed Initiative was formed, was quite different from that which is now evolving. A regulated local carrier environment existed consisting of the seven regional Bell operating companies (RBOCs) along with some non-Bell companies such as GTE, which provided tariffed local telephone services throughout the U.S. Long distance services were being provided by AT&T, MCI, and Sprint in competition with each other. Cable television companies had not yet begun to expand their services beyond simple residential television delivery, and direct broadcast satellite services had not yet been successfully established. And while some independent research and development activities had been established within some of the RBOCs, the seven regional carriers continued to fund Bellcore as their common R&D laboratory.
With the passage of the Telecommunications Act of 1996, a more competitive telecommunications industry now seems likely. Mergers and buy-outs among the RBOCS are taking place, cable companies have begun to offer Internet access, and provisions for Internet telephony have begun to be accommodated by Internet service providers.
2.3 Gigabit Networking Research Issues
When the initiative began in 1990, many questions concerning high-speed networking technology were being considered by the research community. At the same time, telephone carriers were struggling with the question of how big the market, if any, might be for carrier services which would provide a gigabit/s service to the end-user. Cost was a major concern here. Research issues existed in most, if not all, areas of networking, including host I/O, switching, flow/congestion and other aspects of network control, operating systems, and application software. Two major questions underlie most of these technical issues: (1) could host I/O and other hardware and software operate at the high speeds involved? and (2) would speed of light delays in WANs degrade application and protocol performance?
These issues can be grouped into three general sets, which are discussed separately below:
· network issues
· platform issues
· application issues
Network Issues
A basic issue was whether existing conceptual approaches developed for lower speed networking would operate satisfactorily at gigabit speeds.Implementation issues were also uppermost in mind. For example, would a radically different protocol design allow otherwise unachievable low-cost implementations. However, most of the conceptual issues were driven by the fact that speed-of-light propagation delay across networks is constant, while data transmission times are a function of the transmission speed.
At a data rate of 1 Gbps, it takes only one nanosecond to transmit one bit, resulting in a link transmission time of 10 microseconds for a 10 kilobit packet. In contrast, for the 50 Kbps link speeds in use when the Arpanet was first designed, the same 10 kilobit packet has a transmission time of 200 milliseconds. The speed-of-light propagation delay across a 1000-mile link for either case, on the other hand, is on the order of 10 milliseconds. The result is that, whereas in the Arpanet case propagation delay is more than an order of magnitude smaller than the transmission time, in the gigabit network the propagation time is more than three orders of magnitude larger than the transmission time!
This difference has both positive and negative consequences. On the positive side, store-and-forward delays introduced by packet switches and routers along an end-to-end path are directly related to transmission time, causing them to become very small at gigabit speeds (barring unusual queuing situations). This removes a major problem inherent in the early Arpanet for packetized voice and other traffic having low delay requirements, since at gigabit speeds the resulting cumulative transmission delays effectively disappear relative to the propagation delay over wide-area distances.
On the negative side, the very small packet transmission time means that information sent to the originating node for feedback control purposes may no longer be useful, since the feedback is still subject to the same propagation delay across the network. Most networks in place in 1990, and particularly the Internet, relied on window-based end-to-end feedback mechanisms for flow/congestion control, for example that used by the TCP protocol. At 50 Kbps, a 200 millisecond packet transmission time meant that feedback from a destination node on a cross-country link could be returned to the sender before it had completed the transmission, causing further transmissions to be suppressed if necessary. At 1 Gbps, this type of short-term feedback control is clearly impossible for link distances of a few miles or more.
The impact of this feedback delay on performance is strongly related to the statistical properties of user traffic. If the peak and average bandwidth requirements of individual data streams are predictable over a time interval which is large relative to the network’s roundtrip propagation delay, then one might expect roundtrip feedback mechanisms to continue to work well. On the other hand, if the traffic associated with a user `session’, such as a file transfer, persists only for a duration comparable to or less than the roundtrip propagation time, then end-to-end feedback will be ineffective in controlling that stream relative to events occurring within the network while the stream is in progress. (And while we might look to the aggregation of large numbers of users to provide statistical predictability, the phenomenon of self-similar data traffic behavior has brought the prospect of aggregate data traffic predictability into question.)
Another control function impacted by the transmission/propagation time ratio is that of call setup in wide-area networks using virtual circuit (VC) mechanisms, for example in ATM networks. The propagation factor in this case can result in a significant delay before the first packet can be sent relative to what would otherwise be experienced. Moreover, for cases in which the elapsed time from the first to last packet sent is less than the VC setup time, inefficient resource utilization will typically result.
The transmission/propagation time ratio also impacts local area technologies. The performance of random access networks such as ethernet is premised on this ratio being much greater than one, so that collisions occurring over the maximum physical extent of the network can be detected at all nodes in much less than one packet transmission time. A factor of 100 increase from the original ethernet design rate of 10 Mbps to 1 Gbps implies that the maximum physical extent must be correspondingly reduced or the minimum packet size correspondingly increased, or some combination of the two, in order to use the original ethernet design without change.
More generally, as new competing technologies such as HIPPI or all-optical networks are introduced to deal explicitly with gigabit speeds, and with the prospect of still higher data rates in the future, issues of scalability and interoperability become increasingly important. Questions of whether ATM and SONET can scale independently of data rate or are in fact constrained by factors such as propagation delay, whether single-channel transmission at ever higher bit rates or striping over lower bit-rate multiple channels will prove more cost-effective, and how interoperability should best be achieved are important questions raised by the push to gigabit networking and beyond.
Along a somewhat different dimension, the proposed use of distributed shared memory (DSM) as a wide-area high speed communication paradigm instead of explicit message passing raised a number of issues. DSM attempts to make communication among a set of networked processors appear the same as if they were on a single machine using shared physical memory. A high bandwidth is required between the machines to allow successful DSM operation, and this had been achieved for local area networking environments. Issues concerning the application of DSM to a wide-area gigabit environment included how to hide speed-of-light latency so that processors do not have to stop and wait for remote memory updates and how far DSM could/should extend into the network; for example, should DSM be supported within network switches? Or, at the other extreme, should it exist only above the transport layer to provide a shared memory API for application programmers.
Platform Issues
A second set of issues concerns the ability of available computer and other technologies to support protocol processing, switching, and other networking functions at gigabit speeds. We use platform here very generally to mean the host computers, switching nodes internal to a network, routers or gateways which may be used for network interconnection, and specialized devices such as low level interfacing equipment.
For host computers the dominant question is the amount of resources required to carry out host-to-host and host-to-network protocol processing — in particular, could the computers available in 1990 support application I/O at gigabit rates, and if not at what future point might they be expected to?
Because of the dominance of TCP/IP in wide-area data networking by 1990, a question frequently asked was whether TCP implementations would scale to gigabit/s operation on workstation-class hosts. Some researchers claimed it would not scale and would have to be replaced by a new protocol explicitly designed for efficient high speed operation, in some cases using special hardware protocol engines. Others did not go to this extreme, but argued that outboard processing devices would be required to offload the protocol processing burden from the host, with the outboard processing taking place either on a special host I/O board or on an external device. Still others held that internal TCP processing at gigabit rates was not a problem if care was taken in its implementation, or that hardware trends would soon provide sufficient processing power.
For network switching nodes, a key question in 1990 was whether hardware switching was required or software-based packet switching could be scaled up to handle gigabit port rates and multi-gigabit aggregate throughputs. Another important question was how much control processing could reasonably be provided at each switch for flow/congestion control and Quality-of-service algorithms that require per-packet or per-cell operations. Routers and gateways were subject to much the same questions as internal network switches.
Switching investigations were largely focused on detailed architectural choices for fixed-size ATM cell switching using a hardware paradigm, with the view that the fixed size allowed cost-effective and scalable hardware solutions. Issues concerned whether a sophisticated Batcher-Banyan design was necessary or relatively simple crossbar approaches could be used, how much cell buffering was needed to avoid excessive cell loss, whether the buffers should be at the input ports, output ports, intermediate points within the switch structure, or some combination of these choices, and whether input and output port controller designs should be simple or complex.
For variable-length PTM switching, issues concerned how to develop new software/hardware architectures to distribute per-port processing at gigabit rates while efficiently moving packets between ports, and how to implement network control functions within the new architectures. A key question was how much, if any, specialized hardware is necessary to move packets at these rates.
Other platform issues concerned the cost of achieving gigabit/s processing in specialized devices such as those needed for interworking different transmission technologies or for SONET crossconnect switching, and whether it was reasonable to accomplish these functions by processing data streams at the full desired end-to-end rate or alternatively to stripe the aggregate rate over multiple lower speed channels.
Software issues also existed within host platforms over and above transport and lower layer protocol processing. One set of issues concerned the operating system software used by each vendor, which like most platform hardware was designed primarily to support internal computation with little, if any, priority given to supporting efficient networking. In addition to questions concerning the environment provided by the operating system for general protocol transactions, an important issue concerned the introduction of multimedia services by external networks and whether sufficiently fast software response times could be achieved for passing real-time traffic between an application and the network interface.
Another host platform software issue concerned the presentation layer processing required to translate between data formats used by different platforms, for example different floating point formats — because the translation must in general be applied to each word of data being transferred, it had the potential for being a major bottleneck.
Highly parallel distributed memory computer architectures which were coming into use in 1990 presented still another set of software issues for gigabit I/O. These architectures consisted of hundreds or thousands of individual computing nodes, each with their own local memory, which communicated with each other and the external world through a hardware interconnection structure within the computer. This gave rise to a number of questions, for example whether TCP and other protocol processing should be done by each node or by a dedicated I/O node or both, how data should be gathered and disseminated between the machine I/O interfaces and each internal node, and how well the different hardware interconnect architectures being used could support gigabit I/O data rates.
Application Issues
The overriding application concern for host-to-host gigabit networking was what classes of applications could benefit from such high data rates and what kind of performance gains or new functionality could be realized.
Prior to the Initiative, many people claimed to have applications needing gigabit/s rates, but most could not substantiate those claims quantitatively. It was the competition for participation in the Initiative that led to ideas for applications that required ~ Gb/s to the end user. Essentially all the applications which were selected had in common the need for supercomputer-class processing power, and these fell into two categories: ‘grand challenge’ applications in which the wall-clock time required to compute the desired results on a single 1990 supercomputer typically ranged from days to years, and interactive computations in which one or more users at remote locations desired to interact with a supercomputer modeling or other computation in order to visually explore a large data space.
The main issue for grand challenge applications was whether significant reductions in wall-clock solution time could be achieved by distributing the problem among multiple computers connected over a wide-area gigabit network. Here again, speed-of-light propagation delay loomed large — could remote processors exchange data over paths involving orders of magnitude larger delays than that experienced within a single multiprocessor computer and still maintain high processor utilization?
While circumventing latency appeared to be a major challenge, another approach offered the promise of major improvements for distributed computing in spite of this problem. This was the prospect of partitioning an application among heterogeneous computer architectures so that different parts of the problem were solved on a machine best matched to its solution. For example, computations such as matrix diagonalizations were typically fastest on vector architectures, while computations such as matrix additions or multiplications were fastest on highly parallel scalar architectures. Depending on the amount of computation time required for the different parts on a single computer architecture, a heterogeneous distribution offered the possibility of superlinearspeedups. (One definition of superlinear speedup is “an increase by more than a factor of N in effective computation speed, using N machines over a network, over that speed which the fastest of the N machines could have achieved by itself.)
Thus issues for this application domain included how to partition application software so as to maximize the resulting speedup for a given set of computers, which types of computers should be used for a particular solution, what computation granularities should be used and what constraints are imposed by the application on the granularities, and how to manage the overall distributed problem execution. The last question required that new software tools be developed to assist programmers in the application distribution, provide run-time execution control, and allow monitoring of solution progress.
The second class of applications, interactive computations, can range from a single user interacting with a remote supercomputer to a large number of collaborators sharing interactive visualization and control of a computation, which is itself distributed over a set of computing resources as described above and which may include very large distributed datasets. An important issue for this application class is determining acceptable user response times, for example 100 milliseconds or perhaps one second elapsed time to receive a full screen display in response to a control input. This should in general provide more relaxed user communication delay constraints than the first application class, since these times are large enough to not be significantly impacted by propagation delay, and will also remain constant as future computation times decrease due to increased computing power.
Other issues for remote visualization include where to generate the rendering, what form the data interface should take between the data generation output and the renderer, how best to provide platform-independent interactive control, and how to integrate multiple heterogeneous display devices. For large datasets, an important issue is how to best distribute the datasets and associated computational resources, for example performing preprocessing on a computer in close proximity to the dataset and moving the results across the network versus moving the unprocessed data to remote computation points.
Each of the above issues were examined in a variety of networking and application contexts and are described more fully in the referenced testbed reports. The investigations and findings are summarized in Section 4.
3 Structure and Goals
The origins of the testbed initiative date back to 1987, when CNRI submitted a proposal to NSF and was subsequently awarded a grant to plan a research program on very high speed networks. The original proposal, which involved participants from industry and the university research community, was written by Robert Kahn of CNRI and David Farber of the University of Pennsylvania. Farber later became an active researcher on the follow-on effort, while CNRI ran the overall initiative. As part of this planning, CNRI issued a call for white papers in October 1988. This call, published in the Commerce Business Daily, requested submissions in the form of white papers from organizations with technological capabilities relevant to very high speed networking.
The selection of organizations to participate in the resulting testbed effort was carried out in accordance with normal government practices. A panel of fourteen members, drawn largely from the government, was assembled to review the white papers and to make recommendations for inclusion in the program. Those recommendations formed the basis for determining the government-funded participants. CNRI then worked with telecommunications carriers to obtain commitments for wide-area transmission facilities and with others in industry to develop a cohesive plan for structuring the overall program.
A subsequent proposal was submitted to NSF in mid-1989 for government funding of the non-industry research participants, with the wide-area transmission facilities and industrial research participation to be provided by industry at no cost to the government. A Cooperative Agreement, funded jointly by NSF and DARPA, was awarded to CNRI later that year to carry out testbed research on gigabit networks. The research efforts were underway by Spring 1990. Government funding over the resulting five-year duration of the project totaled approximately $20M, with these funds used primarily for university research efforts, with total value of industry contributions over this period estimated to be perhaps 10 or 20 times greater than the Government funding..
3.2 Initiative Management
The overall effort was managed by CNRI in conjunction with NSF and DARPA program officials. Within NSF, Darleen Fisher of the CISE directorate, provided program management throughout the entire effort. A series of program managers, beginning with Ira Richer, were responsible for the effort at DARPA. Many others at both NSF and DARPA were also involved over the duration of the effort. In addition, each testbed had its own internal management structure consisting of at least one representative from each participating organization in that testbed; the particular form and style of internal management was left to each testbed’s discretion.
The coordinating role of a lead organization, played by CNRI, was essential in helping to bridge the many gaps between the individual research projects, industry, government ag encies and potential user communities. At the time this effort began, there did not appear to be a clearly visible path to make this kind of progress happen.
To provide an independent critique of project goals and progress, an advisory group was formed by CNRI consisting of six internationally recognized experts in networking and computer applications. A different, yet similar by constituted, panel was formed by NSF to review progress during the second year of the project.
Administrative coordination of the testbeds was carried out in part through the formation of the Gigabit Testbed Coordinating Committee (“Gigatcc”), made up of one to two representatives from each participating testbed organization and CNRI/NSF/DARPA project management. The Gigatcc, chaired by Professor Farber, met approximately 3-4 times per year during the course of the initiative. In addition, each research organization provided CNRI with quarterly material summarizing progress, and each testbed submitted annual reports at the completion of each of the first three years of the initiative. Final reports for each testbed were prepared and are being submitted along with this document.
To encourage cross-fertilization of ideas and information sharing between the testbeds, CNRI held an annual three-day workshop attended by researchers and others from the five testbeds, plus invited attendees from government, industry, and the general networking research community. Attendance at these workshops typically ranged from 200-300 people, and served both as a vehicle for information exchange among project participants and as a stimulus for the transfer of testbed knowledge to industry. CNRI also assisted the U.S. Government in hosting a Gigabit Symposium in 1991,attended by over 600 individuals and chaired by Al Vezza of MIT.
A number of small inter-testbed workshops were also held during the course of the project to address specific testbed-related topics which could especially benefit from intensive group discussion. A total of seven such workshops were held on the following topics: HIPPI/ATM/SONET interworking, gigabit TCP/IP implementation, gigabit applications and support tools, and operating system issues. In addition, an online database was established at CNRI early in the project to make information available via the Internet to project participants about new vendor products relevant to gigabit networking, and to maintain a list of publications and reports generated by testbed researchers.
3.3 The Testbeds
The five testbeds were geographically located around the U.S. as shown in Figure 3-1.
Figure 3-1. Testbed Locations
No comments:
Post a Comment